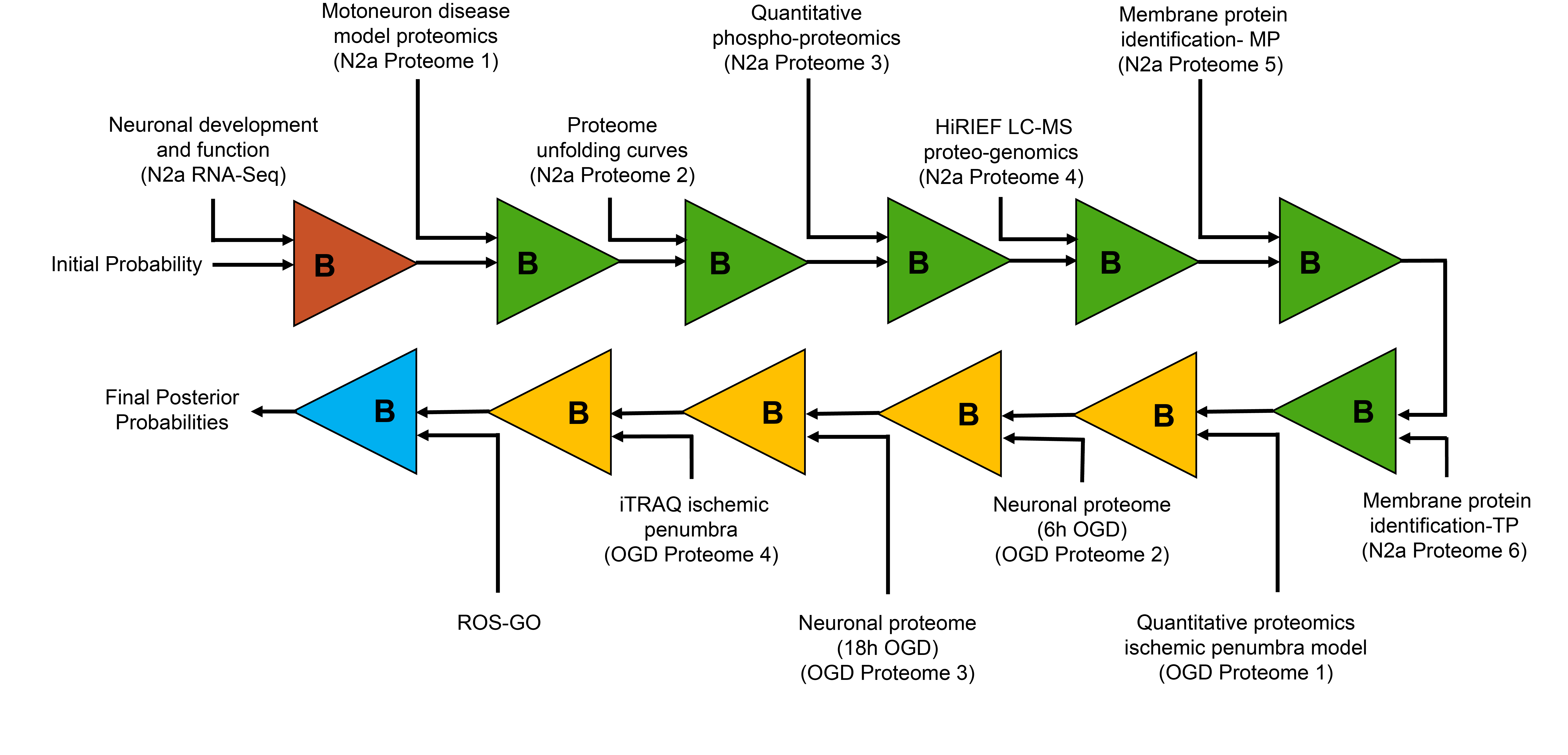
Protein targets of Naringin were acquired from the following databases using filters like target organism - Homo sapiens, Rattus norvegicus, Mus musculus, and target type - single protein. The standard human gene IDs corresponding to the ChEMBL/Uniprot ID/Accession number for the targets were mapped using the ID-mapping feature in Uniprot. Duplicates were eliminated. This created a data vector of length 289 which will serve as the prior probability vector for bayesian analysis